语音识别
活动说明
将音频转换为文字输出,最长 60s。支持格式:pcm 、speex(8k)、speex-wb(16k)、mp3。使用该活动需要联网并确认额度充足
执行逻辑:将上传的音频经过系统处理后转换成文字输出到指定的变量中
属性说明
输入项
音频文件路径
输入需要识别的音频文件路径
语言
[下拉选项]
选择音频文件识别语言,中文或英文
音频格式
[下拉选项]
从下拉框中选择音频的格式,支持pcm、mp3、speex(8k)、speex-wb(16k)
应用领域
[下拉选项]
选择识别的音频在日常应用中属于的领域,有助于语音识别率
输出项
输入需要接收语音识别结果的变量,提供两种输入方式,可二选一:
结构化字符串
输入变量,用于接收语音识别结果
json字符串
输入变量后,接收的语音识别结果会以json结构展示
使用示例
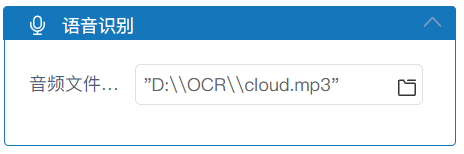
属性栏设置:
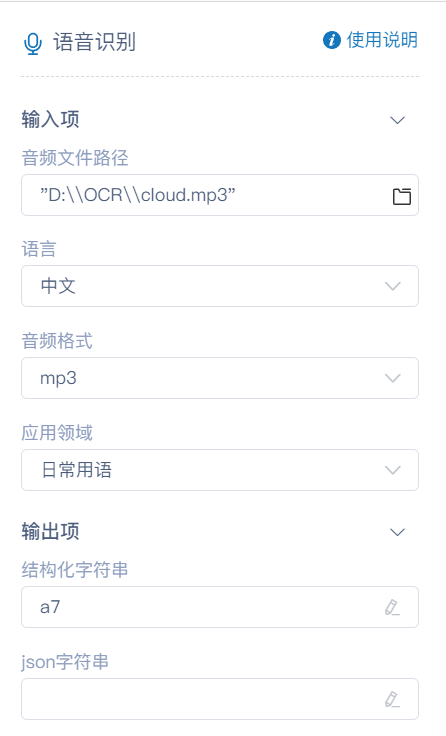
运行结果:

注意事项
语音识别的成功率与音频文件的清晰程度有关,越清晰识别度越高